この記事は クラスター Advent Calendar 2022 (1枚目) 20日目の記事です。
クラスター社で、サーバーエンジニア兼Androidアプリエンジニアをしている kyokomi です。 (ちなみに2枚目の3日目も書いてますので、よろしけばそちらもどうぞ => とある中距離通勤の基本リモート月1物理出社 )
昨日は 、 @Sixeight の 「クラスター株式会社」に入社しました でしたね。
古参メンバーな自分としては、入って間もないメンバーがすごい速度で馴染んでくれて成果を出しまくっててめちゃありがたいし、自分もまだまだ頑張らないとな〜と身が引き締まる思いです!
そして、“何の変哲もないWeb” そう!まさにそうなんです! 今回話す内容は、その"何の変哲もないWeb"の裏側で使ってるSQLのスロークエリとどう向き合って、どう闘っているのかを紹介したいと思います!!!
前提知識
まず、スロークエリとの闘いについて話す前にクラスター社のWeb API Serverでデータベースがどんな構成でどういう風に利用しているのかを超簡単に最低限必要な情報だけサクッと説明したいと思います。
DBについて
- clusterのDatabaseは、AWSのRDS(Aurora)を使っています
- 現時点では、mainのWriterが1台とreaderが複数台存在する構成になっています
実装について
- サーバーの実装は基本Goです
- ORMapper等は使っておらず、sqlxを使って生のSQLをガリガリ書いてます
レビュー体制
- 新規のクエリなどを追加する場合は、explainとかを貼ってクエリ自体やパフォーマンスで問題がなさそうかチェックしている(ただし、開発環境で用意できる範囲のデータで見ていることがほとんどなので、実際の本番環境相当のデータでは確認できないことがある)
- テーブル構成やindex設計などについては、テーブル作成のDDLをgithub上のPRでレビューしたり、事前にdesign doc(Google Docs)等でもレビューしたりしている
スロークエリとの闘い
しかし、スロークエリは発生してしまう… 前述したようなレビュー体制であっても、スロークエリーの発生を完全に防ぐことできません。
発生してしまう例
例えば…(実話かもしれないし、妄想かもしれない)
- 単純な考慮漏れで、本来貼るはずのindexを忘れてしまった
- カラム追加に伴う変更時にindex設計の考慮が甘かった
- 実際にリリースしたら想定より利用され、データ量の考慮が甘く rowsが爆発した
- データの並び替えなどの仕様変更でスッとクエリを変更してindexが効かなくなっていたことに気が付かなかった(レビューした人も)
- 開発初期で、まだまだデータ量も多くないし工数削減でページネーションの実装を後回しにしていたものが、時間の経過によってindexは効いているが単純に取得するデータ量が多くなってしまった
- さまざまな要因で扱うデータ量が増えていき、IN句に指定するidがすごい件数になっていた
- etc…
推測するな、計測せよ
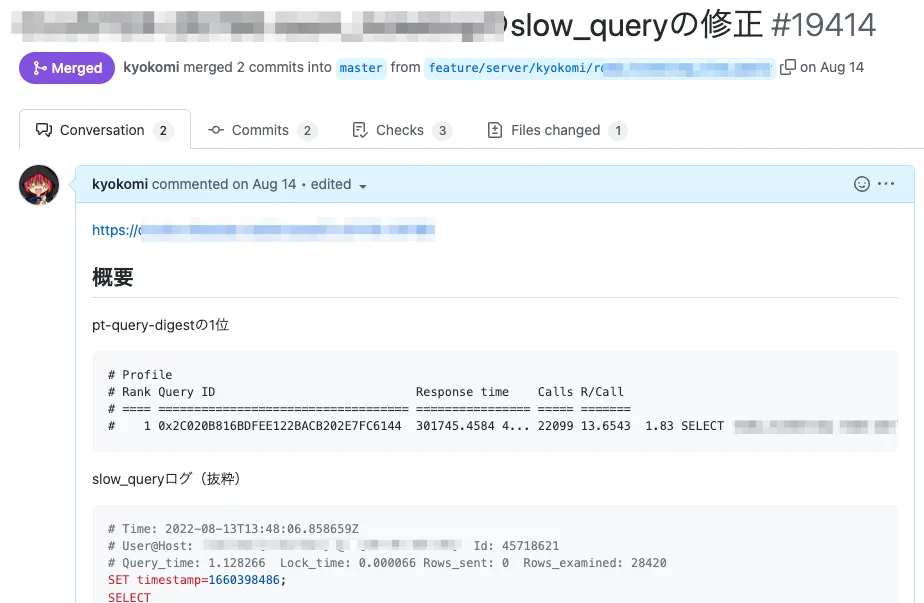
ということで、毎年参加しているISUCONで、よく使って手慣れているツールでもあるpt-query-digestを使ってスロークエリの分析を始めてみました。
すると…「うわっ…このSQL、遅すぎない…?」というのがチラホラ…という感じでした。 (明らかにやばいクエリは、速攻で修正PR出して対応していきました)
〜めでたしめでたし〜
….というわけにはいかず、一時的には解消してますが継続的に見ていかないと、また同じ問題が起きてしまうので、なんとかしたいと思います。
小さく始める「俺がbotだ!!!」
最初は、人力ではじめました。
毎日Slackのリマインダーで自分をメンションし、自分自身がbotになりきって、RDSのダッシュボードからslowquery.logファイルを24時間分ダウンロードして手元で結合し、pt-query-digestに食わせた結果のサマリーをSlackに貼り付けるマンをやりました(早口)

数日でめんどくさくなり限界を迎えてしまいJenkinsのjob化を決意します。
頑張ればaws-cliとかでも何とかできるんですが、Goで書いたほうがレビューやメンテしやすそうだな〜と思いサクッとslowquery.logをダウンロードするツールを作りました。
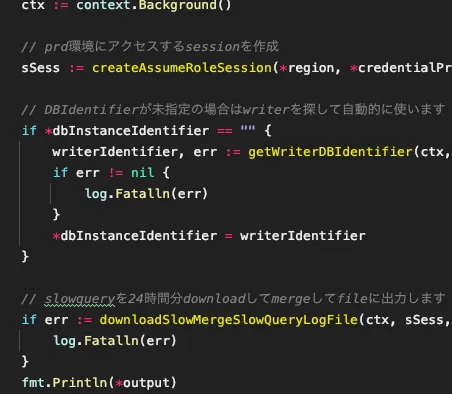
実装はかなりシンプルで、本番環境のRDSのslowquery.logを24時間分forで回してダウンロードして、1つのファイルにマージして出力するだけです。
※実装イメージ(抜粋です)
あとは、これをJenkinsのjob側のshellでpt-query-digestに食わせるだけです。
そうなってくると次は、slackへの投稿やりたくなりますよね?
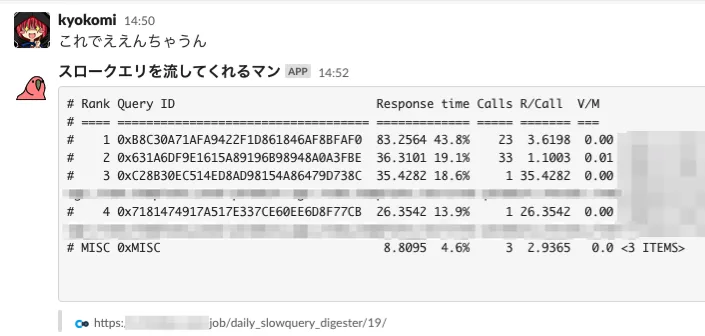
ちなみにこのとき知ったんですが、 pt-query-digest実行時の引数に --report-format profile を指定するとランキング部分だけ出力してくれるのでめっちゃ便利です(最初はgrepして頑張ってランキング部分以外を削ってました笑)
参考) https://docs.percona.com/percona-toolkit/pt-query-digest.html#output
毎日自動で実行してSlackに通知
最後に、このjobをスケジュール実行するようにして完成です!

最終的にはこんな感じになりました 🎉🎉🎉 (Read専用のインスタンスとかもあるので複数通知してます)
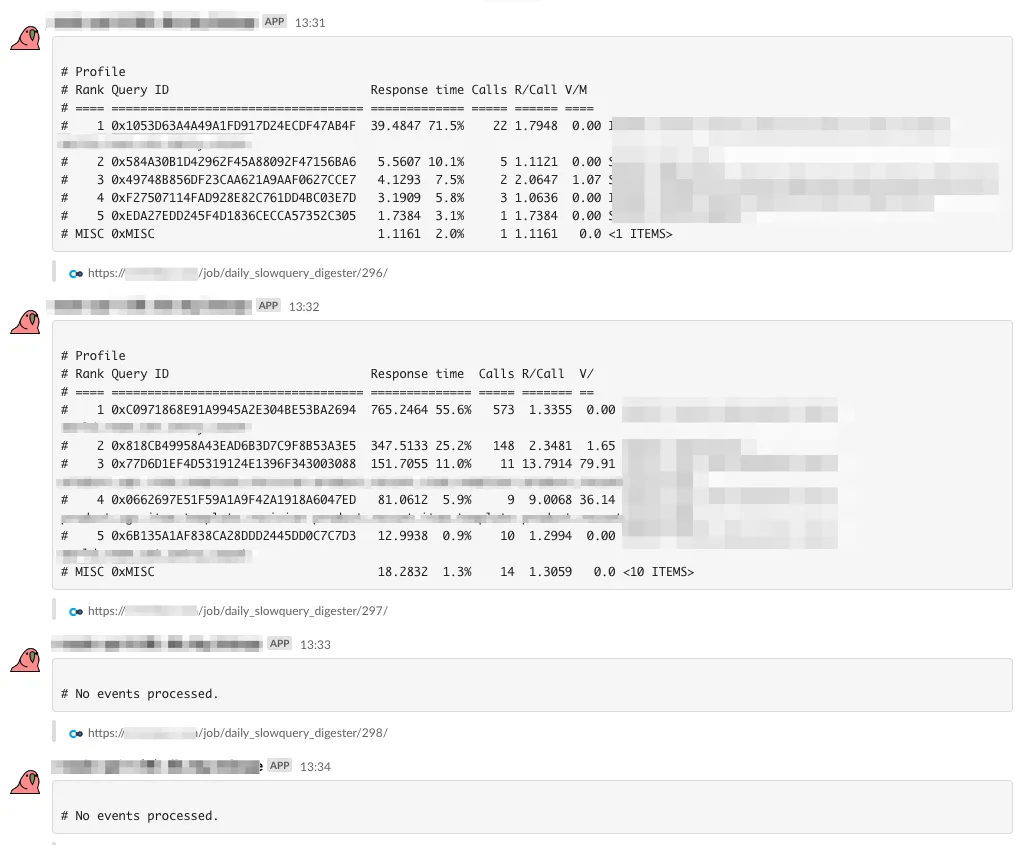
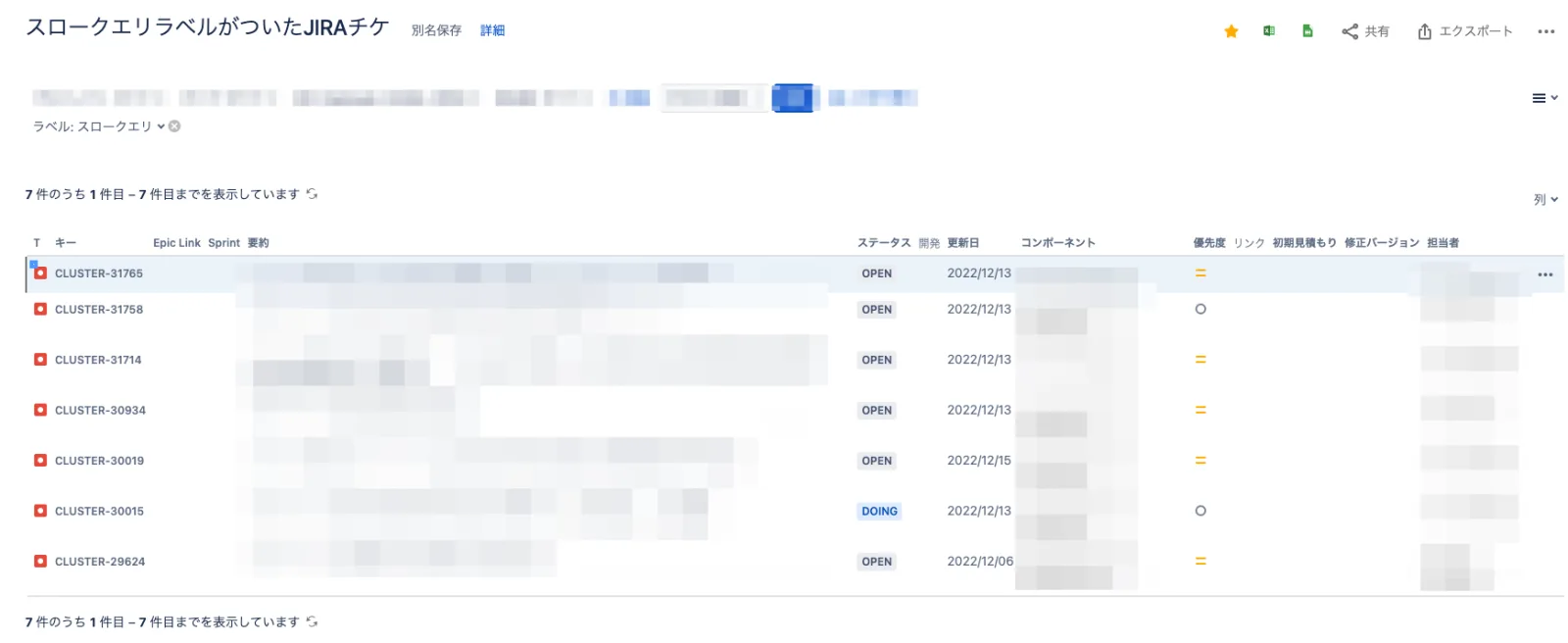
あとはコレをデイリーで確認して、初見スロークエリはJIRAに手動で起票して関係してそうなチームをアサインして改善していくという感じの改善フローが完成です!!!
まとめ
- スロークエリが発生しないようにするのは難しい
- まずは、計測!!
- 基本的に、小さくコツコツ初めていこう
- 誰でも見れる/対応できる状況にしよう
- そして自動化して自分の手から離しましょう!!!
楽して、楽しいSQLライフをお楽しみください〜
明日は、@thara の「子育てとclusterとキャリアパス」ですね!お楽しみに!!